


可灵活使用的6DoF素材
虽然该灵活的制片过程主要针对XR应用,因为捕获的6自由度素材可以在给定的运动范围内,并且从任何角度查看。但与此同时,它也可以被用于传统的常规制片流程,只需要在虚拟视角下对所捕获的内容进行框选即可。
内容捕获&修改工具
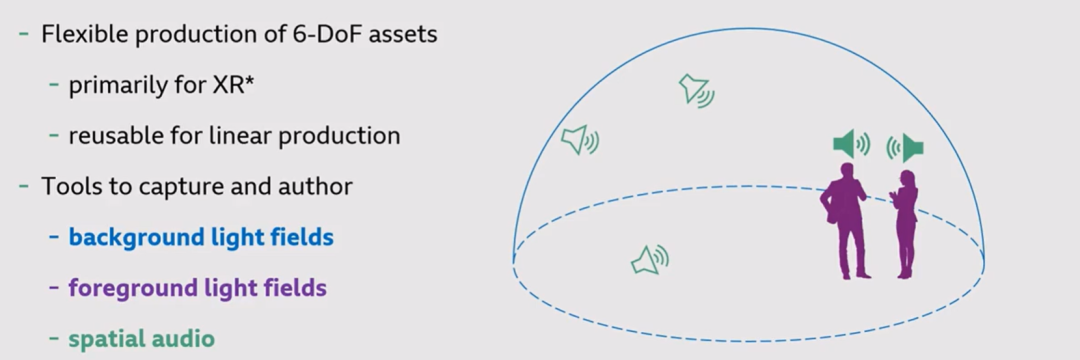
本文开发的用于内容捕获和修改的工具主要被分为三个部分:
背景光场(background light fields) 捕获背景环境
前景光场(foreground light fields) 捕获主要的演员、演讲者的动作
空间音频(spatial audio) 捕获环境中与前景相关联的音频,以及背景音频
背景光场
本文使用了一个非常简单的背景捕捉系统,他们使用了一个 360 度相机,在一个水平圈内缓慢转动,如图所示:

根据光照条件,每转一圈它可以捕获大约 1800 帧。作者以每秒 30 或 60 帧的速度拍摄曝光度锁定的视频内容,这样捕获过程只需一分钟或 30 秒。
另一个非常重要的特点是,其数据集形式为单个简单的视频。这是一个非常好的属性,因为可以重用所有现有的视频工具和工作流程来存储传输编辑或更改数据集。通过捕获水平圆形数据集上的 1800 帧,作者可以通过简单地重新组合或插值在实际由小倾斜捕获的光线之间重新组合或插值,在捕获圈内的任何位置创建已知视图。
背景光场的完整工作流程如下:

作者使用之前提到的 360 度相机捕捉环境,并且进行简单,主要包括将源视频修剪到正确的长度,使其包含完整的分辨率,然后将视频重新采样到所需的分辨率帧速率。Structure-from-motion是可选的步骤,作者已经尝试过不同的现成开源工具(COLMAP, AliceVision等)来执行此操作,它们都得到了非常相似的结果。这种粗略的重建可能对下一步有作用。
在下一步中,作者将引入一个场景代理,该代理主要由地面和几个表示主要场景结构的图元组成。它可以完全从头开始构建,而如果有点云或某种 3D 重建有助于将这些平面和盒子放置在场景中,也可以依赖他们。但正如此前所提到的,这并不是绝对必要的。这个场景代理的主要目的是避免渲染中的畸变,并且还允许前景对象与背景交互。例如,如果动画角色要经过背景对象,则只能在场景代理到位时完成。
至于渲染部分,作者将渲染任务在Unity引擎中实现,在他们当前的实验中,在适合当前虚拟现实头显的分辨率下,达到了远远超过每秒 100 帧的帧速率,渲染算法本身的工作原理如下:

作者首先选择包含当前像素对应的光线的源视图,然后作者根据来自作者手动放置在场景中的几何代理的皮肤深度对源视图进行采样。采样的 source ray 和 Rendered Ray 之间的夹角非常锐利,这意味着采样过程对深度误差非常不敏感,这意味着在放置几何代理时不需要非常精确。
由于在捕捉过程中捕捉相机会移动,因此场景通常仍然需要完善,否则作者会在合成输出中得到重影伪影。尽管如此,作者可以通过改变对源视图进行采样的方式来支持有限的背景运动。对于动态对象,作者不是对空间上最近的源视图进行采样,而是对时间上最接近的源视图进行采样。该功能仍然用Unity实现,使用了引擎中可应用于动态对象的shader。通过简单地循环具有动态对象和镜头的源视图,该系统可以创建背景运动的错觉。除此之外,利用类似的技术,对于其他周期性或无规律性的动态物体,该系统还可以达成“Yoyo”效果。
前景光场
采集设备采用一个麦克风-相机阵列,它由 11 个摄像头和 16 个麦克风组成,旨在捕捉动态的前景表演。它的设计非常轻巧,可以安装在普通的三脚架上,操作起来非常像广播摄像机,操作员可以使用中央视图来构图。

作者的前景光场的工作流程如下:

捕获步骤后,下一步是对成对视角的立体视图进行深度估计,然后根据置信度度量将其融合在一起,该置信度度量也是从立体匹配过程中得出的。语义分类步骤是使用卷积神经网络执行的,该网络识别场景中的不同对象并为其分配唯一标签。然后使用细化深度图以及背景前景和对象间分割的超像素算法对这些单独的对象进行分割。而最终的重建是 3D 网格的形式。它是动画的,可以放置到虚拟场景中。
随后讲者展示了一个demo,观看者可以以任意角度、从任意位置观看该场景,并且还可以查看该场景的几何代理场景。经过对比,可以发现如果没有采用几何代理限制,任何视角下的图片都将有非常严重的畸变。最后,讲者展示了一个前景与背景交互的例子,可以发现因为有着背景的几何限制(尤其是地面平面的先验),被插入场景的前景演员的战立非常自然。
空间音频
本工作的空间音频技术的工作流主要来源于Audio Definition Model(ADM),它是广播行业开发的一种开放标准,用于描述音频场景的内容和格式。这包括 3D 属性,例如 3D 中的源位置和音频对象的范围。ADM 描述可以方便地嵌入到波形文件(.wav)中,以便于文件交换,作者大量使用它,甚至在不同处理阶段之间传递空间音频数据。
空间音频的完整工作流如下:

前景声源是使用前面提到的捕获设备上的 16 个麦克风捕获的。然后使用新的视听跟踪器跟踪声源,该跟踪器结合了音频三角测量的结果和基于 Openpose 的视觉跟踪器的结果。这两者的结合显著提高了单个声音对象估计的 3D 位置的可靠性和准确性。然后使用Beamforming 来分离那些对象,使得作者有干净的信号,这些信号直接与场景中的各个声源相关联。为了模拟背景环境的声学,作者使用 Ambisonic 麦克风来捕捉房间或环境的脉冲响应。然后作者使用作为该项目的一部分开发的房间模型,将房间脉冲响应转换为单独的音频对象,用于直接路径和场景中的早期反射和延迟混响。
所以在这个阶段,音频场景所需的所有成分已经都被获得了,它们都是 ADM 格式,制片者可以继续在EAR制作套件中编辑它们。EAR制作套件是一组用于数字音频工作站的开源插件。值得一提的是,EAR代表 EBU ADM Renderer,它是 ADM 播放的参考实现。EAR 的双耳版本,被称之为 BEAR,用于将 ADM 场景渲染到 2 个耳机,在编辑阶段用于监控音频场景中发生的情况,也用于最终的虚拟现实输出。有一个Unity中的插件,实现了 BEAR 渲染器,可以将其放入Unity场景中并在那里渲染空间音频。
文件来源:媒矿工厂
