


来源:SPIE2021
作者:Nicola Giuliani, Biao Wang等
内容整理:胡经川
本文介绍了一种基于神经网络的帧生成技术,并将它应用在视频编码方案中。基于此方案提出了一种新的帧类型S帧,并且介绍了如何将S帧自适应地插入到GOP中来进一步减少时域冗余。实验结果表明,S 帧与自适应 GOP 相结合在PSNR 和 比特节省上表现出巨大的潜力。
目录
视频编码中的帧类型
帧合成技术
自适应 S 帧插入
实验设置与结果
总结
视频编码中的帧类型
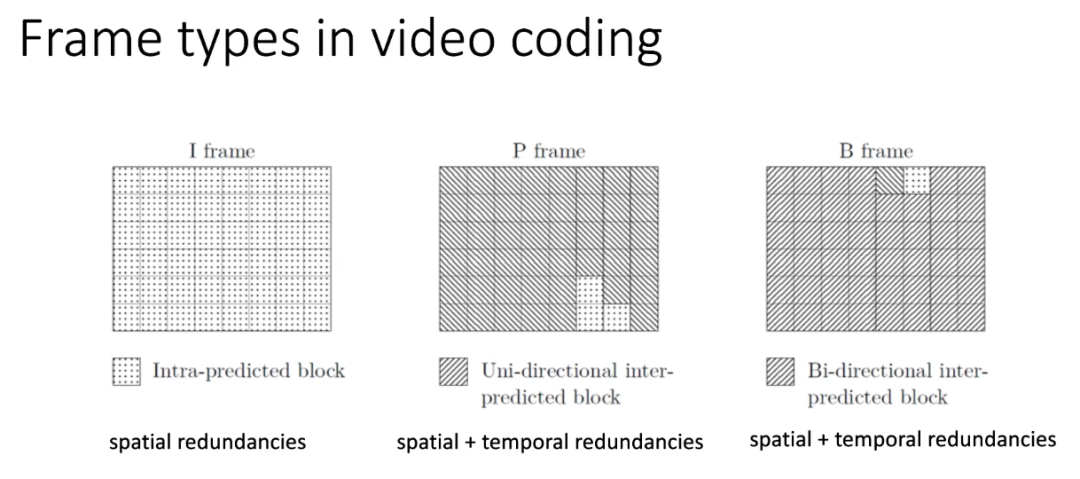
减少视频序列中的冗余是视频压缩的关键要素,这些冗余可分为两类:空间冗余和时间冗余。在图片或帧内,空间邻近的像素具有强相关性,即它们的值很可能相似甚至相同。这种空间统计相关性在帧内预测技术中得到了利用。类似地,相邻帧的像素之间也存在冗余,例如,对象以很小的运动移动,导致连续帧之间的内容几乎没有变化。在这种情况下,空间和时间相近的像素具有很强的相关性,这种相关性被应用在了帧间预测技术中。通过编码运动信息并使用解码的参考帧和运动信息来恢复出相应的帧,从而减少时间冗余并进一步提高编码效率。
根据帧内预测和帧间预测的概念,基于预测块的构成,在视频编码中建立了三种主要的帧类型。在 I 帧中,所有块都是帧内预测的,并且不表现出对其他帧的依赖性;在P 帧中,允许额外的单向帧间预测,其中一个或多个先前帧被用作其参考帧;在 B 帧中,允许额外的双向帧间预测,其中先前帧和未来帧都可以用作其参考帧。关于压缩比,通常 I 帧被压缩得最少,因为没有利用时间冗余。B 帧的压缩效果最好,因为双向预测显著提高了其预测精度。P 帧的比特成本介于 I 帧和 B 帧之间。
I 帧,P 帧和 B 帧排列在一组图片(GOP)中。GOP 可以用两个值来描述:M 和 N。M 值表示两个 I 或 P 帧之间的距离,而 N 表示两个 I 帧之间的距离。由于 I 帧仅依赖于帧内预测,因此就比特而言,它们的成本最高。因此,尝试将 I 帧的数目保持在最小值是合理的。然而,必须为 N(两个 I 帧之间的距离)找到一个折衷方案,因为 I 帧对于提供随机接入点是必不可少的,并且提高了错误恢复能力,在场景改变时是需要的。当然,除了进一步增加 N 值之外,还可以通过增加 M 值,即增加 I 帧或 P 帧之间的 B 帧的数目来提高编码效率。然而,这是以增加编码-解码延迟为代价的。
帧合成技术
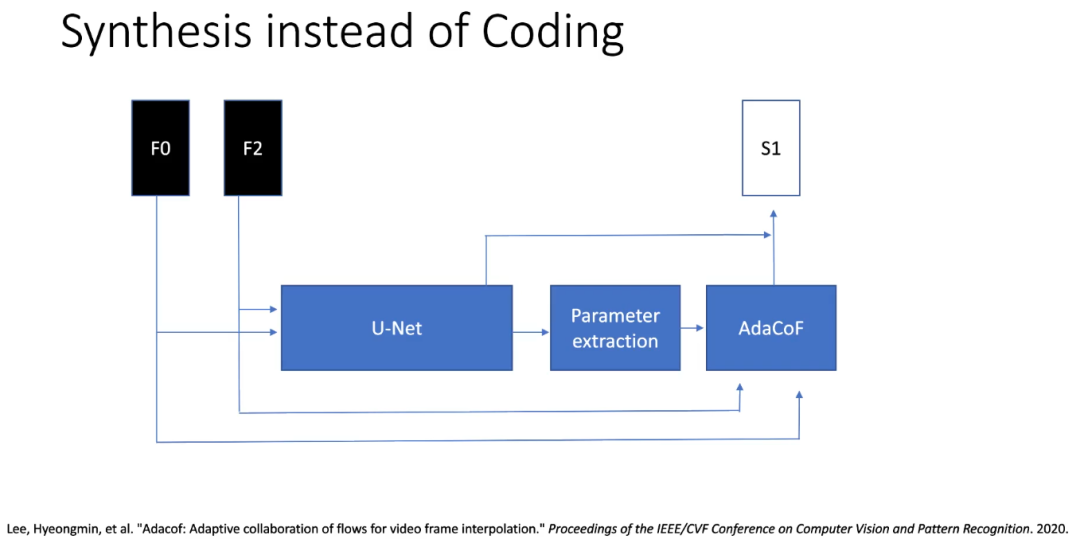
在这项工作中,研究了一种称为 S 帧的新的帧类型。S 帧仅使用规则编码帧 (B、P 或 I)在解码器上进行帧合成,示意图如图 2 所示,其中 表示两个连续的用于参考的帧, 表示利用这两个参考帧,通过双向插值模块合成的中间帧。网络由一个 U-Net 特征提取器和子网络组成, AdaCoF 用于将两个参考帧进行双向扭曲来合成最终的中间帧,而子网络用于估计 AdaCoF 所需的参数。
这种基于合成的帧完全在解码端进行合成,不编码任何运动信息,因此没有比特成本。
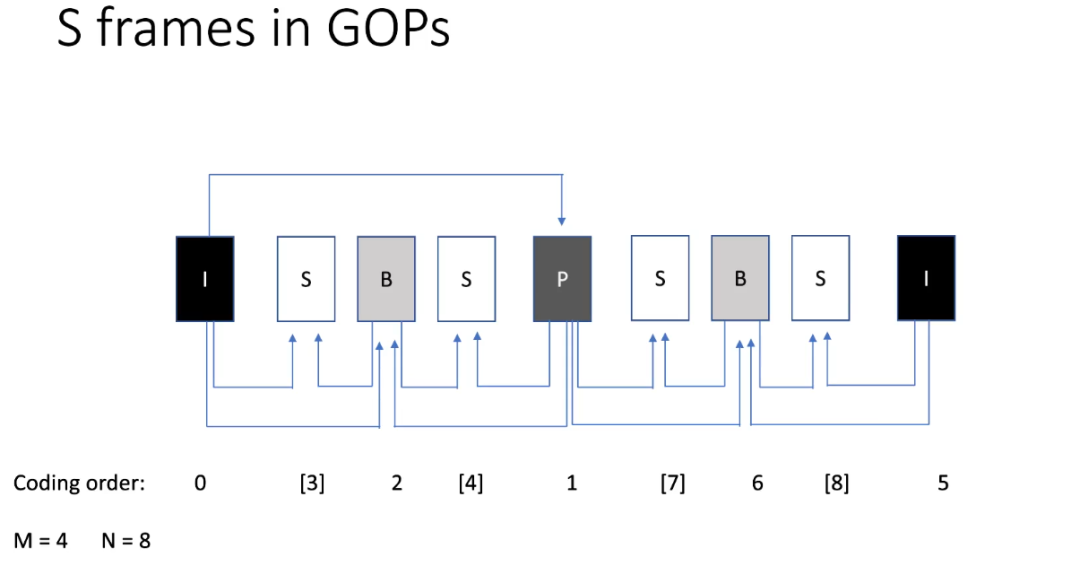
此外还提出了一种在 GOP 中有效插入S帧的算法。自适应插入是根据一个插入准则和一个最大前瞻常数来完成的。仅当满足插入准则时(例如,仅当原始帧和合成帧之间达到图像质量度量的最小阈值时),才会插入合成帧。这使得 S 帧的插入与视频内容相适应。最大前瞻常数设置了连续 S 帧数量的限制,即,前瞻值等于两个规则编码帧(B、P 或 I)之间的最大允许距离。GOP 大小可能是自适应的,因为根据插入的 S 帧的数量,GOP 可能或多或少地增长。
整个算法流程如表 1 所示。该过程从一系列原始帧的序列开始,需要两个额外的输入:最大前瞻常数(ml)和准则函数。首先第一帧被添加到 GOP 缓冲区,编码循环开始。过去的一个参考帧存储在变量 中。然后,在 中定义一组潜在的 (=插入的S帧+1),并且 是 2 的倍数。插入的最佳 S 帧数 初始化为 0。然后,寻找最佳前瞻常数(在 lookaheads 上使用二分查找)。为此,相应地设置 和 限制,并检索目标值 。选择来自未来的第二个参考帧 ,该参考帧与第一个参考帧 之间的距离为 。从原始帧序列 s 中检索 和 之间的目标帧 。然后使用帧插值网络和两个参考帧在与 帧相同的位置生成帧 。如果 和 之间满足条件,则插入的 S 帧的数量 将设置为 。根据该准则调整搜索边界 lo 和 hi。在搜索收敛并找到最佳插入 S 帧数 后,当前帧 idx 的索引将增加插入的 S 帧数,idx 处的下一帧将添加到 GOP 缓冲区。
完成后,使用预定义的编码方案和预定义的 GOP 结构对 GOP 缓冲区进行编码。仅对 GOP 缓冲区中的帧进行编码,而完全跳过 S 帧。为了能够恢复完整的序列,在每个编码帧的头部加上 lookahead 的值(插入的 S 帧数+1)来表示到下一个编码帧的距离。这是必需的,因为根本不发送 S 帧,并且两个编码帧之间的 S 帧数量可能在 0 和最大前瞻常数的值减 1 之间变化。然后通过执行解码恢复编码的 GOP,通过从每个帧对(pair)的第一帧的图片头中读取前瞻来检测 GOP 中每对帧之间的间隙。最后,通过使用帧生成网络和参考帧合成中间帧来填补空白。
为了测试所提出的方法,将其与 compressAI 中可用的基于学习的图像压缩 anchor 模型相结合。由于此编解码器是图像编解码器,在 simple 设置中仅对 I 帧进行编码,而完全忽略 P 和 B 帧。对于插入准则函数,定义了一个基于峰值信噪比 (PSNR) 的标准:
其中, 和 分别是索引 i 处的原始帧和合成帧。而 和 是序列中的第一个原始和编码帧。因此,该准则强制合成帧的质量与编码帧相似,满足该准则的 PSNR 能适应于帧内编解码器的性能。
共设置了三组不同配置的实验,如图4所示:
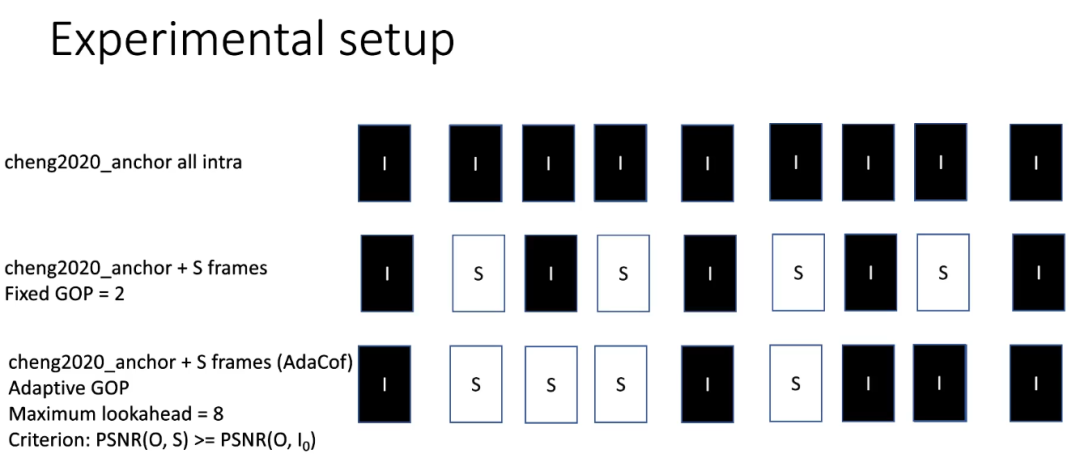
首先是 cheng2020 的全帧内(AI)配置,其次是在大小为 2 的固定 GOP 中使用 S 帧。最后是将最大前瞻常数设置为 8,即两个 I 帧之间的最大 S 帧数不得超过 7 的自适应 GOP 配置。测试均是在 JVET 测试集的 B、C、D、E 和 F class(总共 20 个序列)上进行的。图 5 显示了三种不同编码方案的率失真曲线。很明显,所提出的自适应 GOP 算法不仅比在固定 GOP 中使用 S 帧节省更多的比特,而且还在所有 QP 中保持与等效的所有帧内配置相似的 PSNR。图 5 中还描述了固定和自适应 GOP 大小在每个 class 和不同 QP 的相对增益的详细比较。每个单元格中的第一个值为自适应 GOP 大小,而第二个值为固定 GOP 大小,所有值都表示百分比的相对变化。与固定 GOP 方法相比,自适应方法在 class D 和 class E 中节省了很多比特,同时保持很高的 PSNR,这是通过将这些序列中的 GOP 大小增加到 8 来实现的。相反,如果合成帧的质量不符合 class B/QP=6 中的标准,则不插入 S 帧,从而也比固定 GOP 方法的 PSNR 更高。
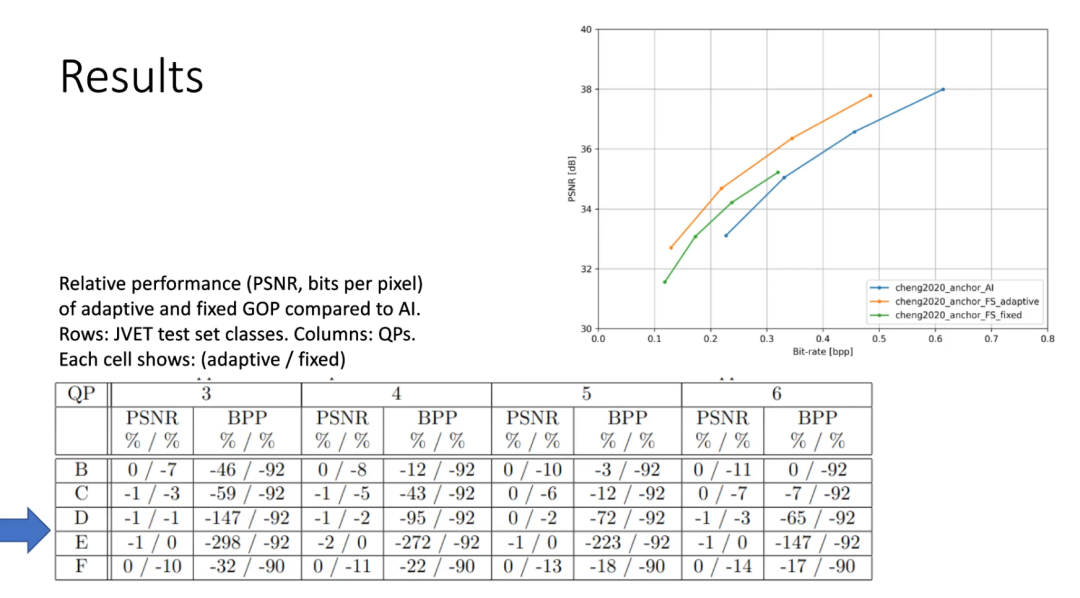

图 6 展示了最终合成帧的视觉效果,左边为合成帧,右边为编码帧。可以看出,尽管合成帧的模糊度稍高,但整体质量与上述标准所强制执行的编码帧相似。
总结
实验结果表明,在固定 GOP 中使用 S 帧可以显着降低比特率,但是帧的质量可能会降低,而所提出的自适应 GOP 方法不仅有助于通过自适应减小 GOP 大小来避免质量下降,而且还通过扩大 GOP 大小进一步增加比特率节省。S 帧的潜力在大多数静态内容的情况下表现最好,如 class E,与所有帧内配置相比,在保持相同 PSNR 的同时,比特率节省可达 300%。
尽管在帧内编解码器使用 S 帧和自适应 GOP 算法相结合的测试设置能表现的增益非常有限,因为它毕竟没有 P 或 B 帧,但结果仍然表明在视频编码中利用 S 帧的巨大潜力。
文章来源:媒矿工厂
